
Diagnosing data quality with machine learning models
Lauren Smith
Feb 19, 2024
Source: J. Chem. Inf. Model. 2023
An interest in energy applications drew Aaron Garrison ('23) into the field of computational chemistry. He joined Zachary Ulissi's research group the summer after his sophomore year. One of Garrison's projects involved trying to train a model that could predict a water splitting catalyst to decrease the costs of green hydrogen, but he found issues with the data.
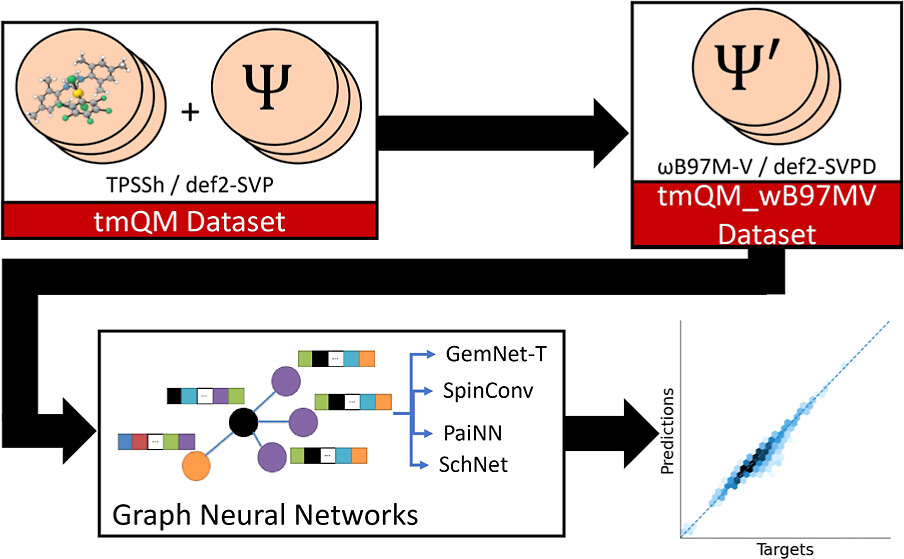
More than 2,500 miles across the country, at Lawrence Berkeley National Laboratory, Sam Blau was generating a new dataset for transition metal complex energies. Blau, a research scientist, had been unsatisfied with an existing dataset, though he didn't have any concrete evidence that it had inconsistencies. He recalculated the dataset at a more rigorous level of theory.
Blau knew Ulissi and Gabe Gomes, faculty in the Department of Chemical Engineering, through their work in similar spaces. A conversation between them connected Blau's work with Garrison's. "It was very serendipitous that I had already calculated this data. Aaron was able to move right over to it, and it solved the problems that he was seeing," says Blau.
The collaborators recently published a paper in the Journal of Chemical Information and Modeling. Garrison led the effort as an undergraduate. He is now a Ph.D. student at Massachusetts Institute of Technology, after earning both bachelor's and master's degrees in chemical engineering at Carnegie Mellon.

Anne Skaja Robinson and Aaron Garrison during the 2023 diploma ceremony for the Department of Chemical Engineering
Garrison and Blau show that machine learning models can be a way to diagnose the quality of a dataset. Previously, there hadn't been a clear way to evaluate the consistency of data in a dataset.
"There's a phrase in data science and machine learning: garbage in, garbage out. People are generating datasets all the time, but it can be very difficult to know if your dataset is reliable or if it contains inconsistent data," says Blau. By trying to train a machine learning model on a dataset, Garrison identified inconsistencies.
The paper also shows the power of pre-training and the chemical transferability of models and data. Garrison started with models that had been trained on a heterogeneous catalysis dataset, from systems in which the catalyst is in a different phase than the reactant. He fine-tuned them on Blau's homogeneous catalysis dataset, and the error metrics improved relative to models trained from scratch. "That's really exciting in terms of the classes of materials we can predict properties for and how well this works as a general method," says Garrison.
During their research, Garrison and Blau noticed that the models saturated when they used only neutral species from the dataset. The models didn't learn anything new when Garrison added more data similar to what he had already added.
Although charged data made up a very small portion of the dataset, its effect on the models was noticeable. When Garrison included the charged data, the error metrics were worse but continued to go down as he added more data. "This means that charged species contain additional chemical information," says Blau. "If the model saturates with neutral-only but keeps learning with charged species, there's more chemistry there, and the information is only accessible when you're dealing with charged species."
If we want machine learning to be able to tackle some of humanity’s most pressing challenges, then we need to extend our models to charged species.
Sam Blau, Research Scientist, Lawrence Berkeley National Laboratory
Blau encourages people building data sets and chemical machine learning models to include species of different charges. Generating data with charged molecules is harder than with neutral molecules, and he hopes the paper starts turning the field in this new direction.
Most state-of-the-art chemical machine learning models are focused on neutral, uncharged molecules. In contrast, applications like batteries, semiconductor manufacturing, atmospheric chemistry, and electrocatalysis involve chemistry of unpaired electrons. "If we want machine learning to be able to tackle some of humanity's most pressing challenges, then we need to extend our models to charged species and species containing unpaired electrons," says Blau.
Blau's group is now working on generating a dataset that has a wider range of charges and species. Additionally, Blau and Gomes are continuing to collaborate on a project trying to leverage information about the electronic structure of metal complexes. Blau says they have only scratched the surface of information from this dataset.
For media inquiries, please contact Lauren Smith at lsmith2@andrew.cmu.edu.